
🌟 Tencent сжали 1.8B модель в 2 бита: 600 МБ веса и Dual-CoT на борту.
Tencent Hunyuan выкатили open-source решение для тех, кто хочет запускать LLM локально на кофеварке.
HY-1.8B-2Bit — модель, которую утрамбовали так плотно, что она занимает меньше места, чем многие современные мобильные приложения.
Модель пилили методом Quantization-Aware Training, который в отличие от PTQ, позволяет адаптироваться к низкой разрядности весов еще на этапе тренировки.
За основу взяли backbone Hunyuan-1.8B-Instruct и жестко сжали веса до 2 бит. При этом эффективный размер в памяти получился эквивалентен модели на 300М параметров, а физический вес получился всего 600 МБ.
Что самое ценное — сохранили фичу Dual-CoT: модель умеет переключаться между быстрым мышлением для простых тасков и глубоким long-CoT для сложных.
🟡Бенчмарки
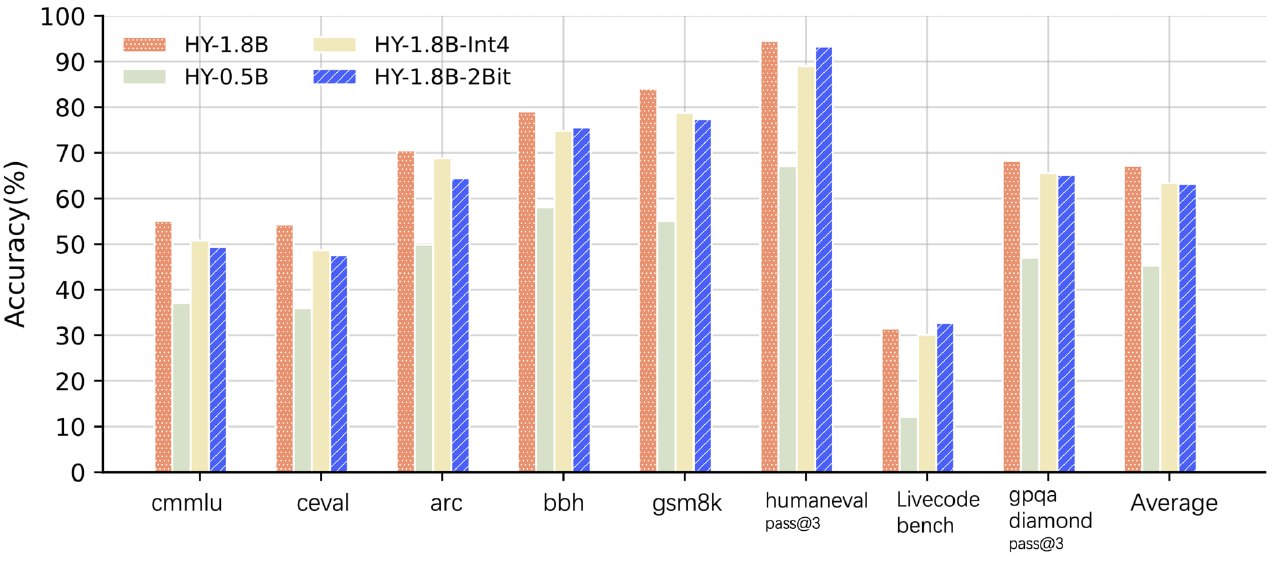
- 🟢По сравнению с fp16-учителем (1.8B), деградация метрик всего ~4%. Это очень мало для 2-битного квантования.
- 🟢Разница в точности на сравнении с INT4 ничтожна — 0.13%, хотя весит модель в 2 раза меньше.
- 🟢Если взять плотную модель на 0.5B параметров, то HY-1.8B-2Bit обходит ее в среднем на 16-17%. На GSM8K разрыв вообще дикий: +22.29%.
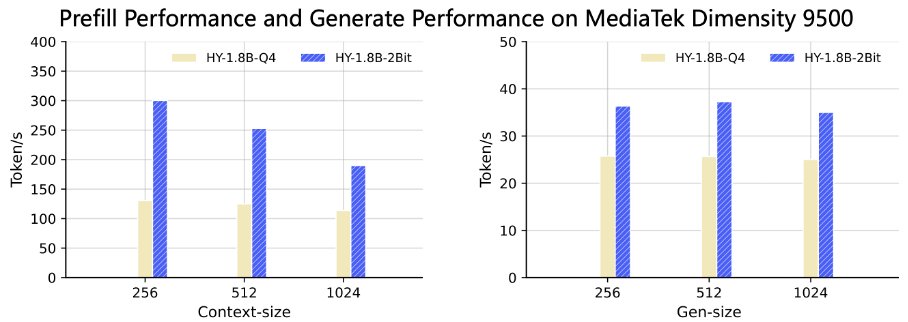
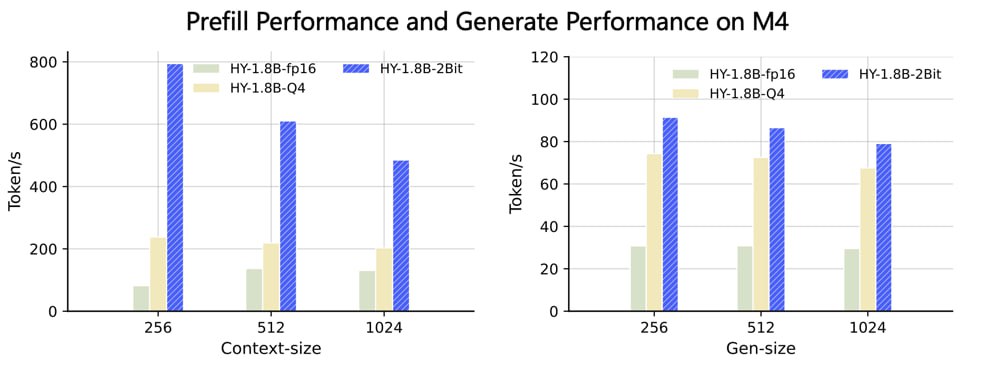
- 🟢Prefill ускорился в 3-8 раз, генерация токенов — в 2-3 раза на поддерживаемом железе.
🟡Жирный нюанс
Текущая реализация требует поддержки инструкций Arm SME2. Это значит, что вся эта красота заведется только на Apple M4 и MediaTek Dimensity 9500.
Если у вас M1/M2 или Snapdragon прошлых поколений — пока мимо. Разработчики обещают подвезти Neon kernel позже.
Кстати, GGUF тоже есть, так что если под рукой есть M4 — можно тестить. Остальным остается ждать оптимизации под старые инструкции.
🟡Модель
🟡GGUF
🟡Техотчет
🖥GitHub
https://t.me/BusinessNetwork_robot?start=G7X296
#AI #ML #SLM #2bitQ #Tencent
📱 Наш Телеграм канал: https://t.me/bninstrum
🔵 Канал VK: https://vk.com/club195425868

