HY-1.8B-2Bit — LLM, которая помещается в смартфон
Tencent открыли исходники HY-1.8B-2Bit — сверхэффективной языковой модели, оптимизированной для работы прямо на устройстве.
Главная идея — максимально снизить размер без серьёзной потери качества.
Что внутри
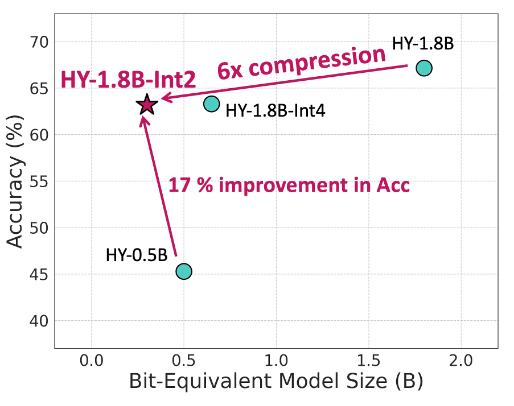
- Базовая модель 1.8B параметров сжата до эффективного размера ~0.3B
- Требует всего ~600 МБ памяти — меньше многих мобильных приложений
- Подходит для edge-инференса: смартфоны, ноутбуки, встроенные устройства
Ключевые технологии
- Ultra-Low-Bit (2-bit) — используется Quantization-Aware Training (QAT)
- Dual Chain-of-Thought — сохранено сложное рассуждение даже при экстремальном сжатии
- Оптимизация под железо — Arm SME2 и современные мобильные чипы
Производительность
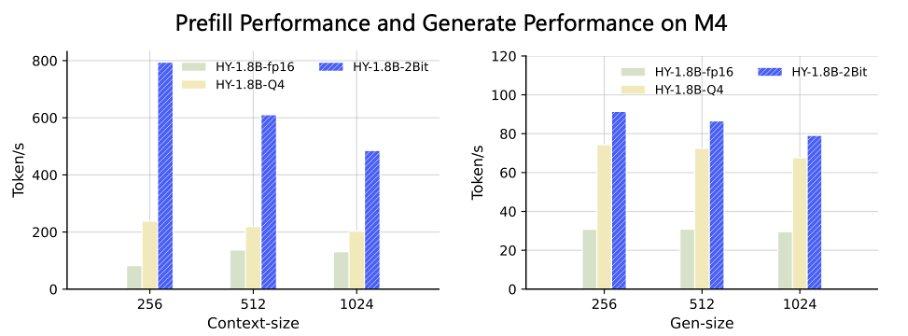
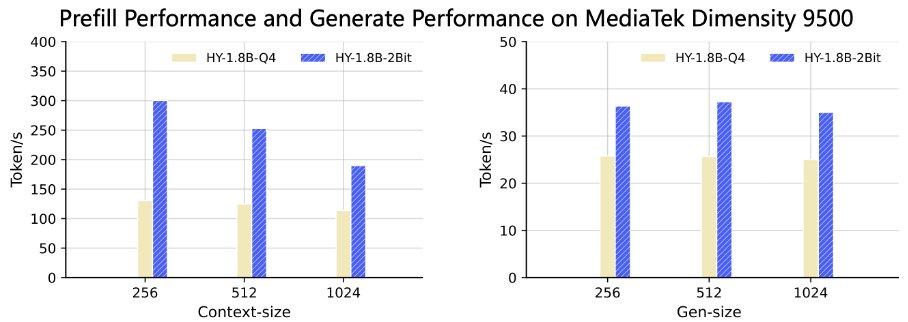
- Prefill: в 3-8 раз быстрее на Apple M4 и MediaTek Dimensity 9500
- Генерация токенов: в 2-3 раза быстрее на устройстве
- В среднем +17% точности по сравнению с моделями аналогичного размера
Почему это важно
Локальные AI-ассистенты без облака становятся реальностью:
- приватность
- офлайн-работа
- низкая задержка
- минимальные требования к памяти
Форматы
- Доступна версия GGUF для интеграции в локальные inference-движки
Проект: https://t.me/BusinessNetwork_robot?start=G7X296
Веса: https://t.me/BusinessNetwork_robot?start=G7X296
GGUF: https://t.me/BusinessNetwork_robot?start=G7X296-GGUF
Technical report: https://t.me/BusinessNetwork_robot?start=G7X296/blob/main/AngelSlim_Technical_Report.pdf
#Tencent
Наш Телеграм канал: https://t.me/bninstrum
Канал VK: https://vk.ru/club195425868
